

Over the last few months I created a fun little toy called Seth’s AI Tools (creative name, huh?), it’s an open source Unity program that has become a playground for me to test a mishmash of AI stuff.
If you click the “AI Paintball” button inside of it, you get the thing shown in the youtube video above.
This shitty game proof of concept generates every character image sprite immediately before it’s used on-screen based on the subject entered by the player. None of the art is included in the download. (well, a few things are, like the forest background and splat effects – although I did make them with this app too)
It’s 100% local and does not use any internet functionality. (behind the scenes, it’s using Stable Diffusion, GFPGAN, ESRGAN, CLIP interrogation, and DIS among other ML/AI stuff tech)
If I leave this running for twelve days, it will have generated and displayed over one million unique images during gameplay.
What can generative art bring to games?
Well, I figured this test would be interesting because having AI make unlimited unique but SIMILAR images of your opponent & teammates and popping them up randomly forces your brain to constantly make judgement calls.
You can never memorize the art patterns because everything is always new content. Sounds tiring now that I think about it.
If you don’t shoot an opponent fast enough, they will hit you. If you hit a friendly, you lose points.
Random thought: It might be interesting to render a second frame where I modify the first image and force a “smile” on it or something, but the whole thing looks like a bad flash game and I got kind of bored of working on it for now.
The challenge of trying to use dynamic AI art inside of a game
It’s neat to type in “purple corndog” and get a brand new picture in seconds. But as far as gamedev goes, what can you really do with a raw AI created image on the-fly?
Uhh… I guess you could…
- Show pictures in a frame on a wall
- Simple art for a “find the matching tiles” or a match three game
- Background art, for gameplay or a title screen
- Texture maps (can be tiled)
Your options are kind of limited.
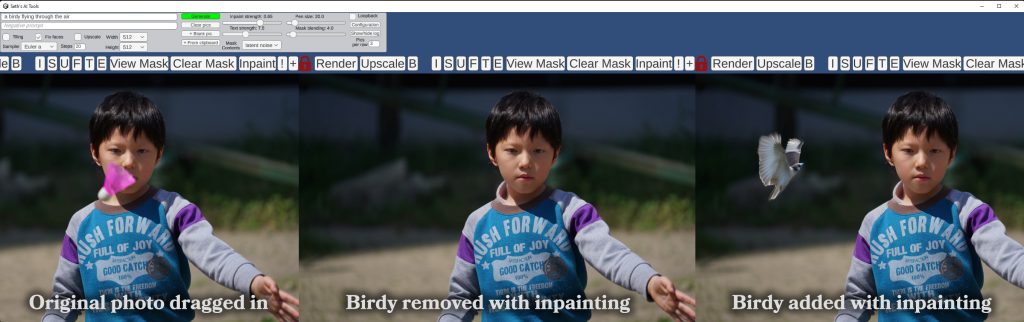
To control the output better, one trick is to start with an existing image, and use a mask to only generate new data in certain parts. In this way, you have a lot more control, for example, you could only change someone’s shirt, and not touch their face.
I used this technique for my pizza screensaver test – I generated a pizza to use as a template once, then asked the AI to only fill in the middle of it (inpainting) without touching the outer crust. This is why every pizza has the same crust.
It works pretty well as I can hardcode the alpha mask to use so it’s a nice circle shaped sprite, don’t have to worry about shapes and edges at all. (see video below)
But with a newer technique called Dichotomous Image Segmentation that I hacked in a few days ago I can now create an alpha masked sprite dynamically in real-time. (A sprite being an object/creature image with a transparent background)
Using DIS works much better than other tests I did trying to use chroma or luma keying. It can pick up someone in a green shirt in front of a green background, for example.
It’s a generally useful thing to have around, even if it isn’t perfect. (and like with everything in this field, better data from more training will improve it)
This video shows a valid use: (I call it “removing background” in the video below, but it’s the same thing)

Now moving on to the AI Paintball demo.
This isn’t a Rorschach ink blot test, it’s the starting shape I use to create all the characters in the AI Paintball test.
This image is the target of inpainting with a given text prompt, the background is removed (by creating an alpha mask of the subject) and voilà, there’s your chipmunk, skeleton, or whatever, ready to pop-up from behind a bush.
A note on the hardware I’m using to run this
I’m using three RTX 3090 GPUs, this is how I can generate an image per second or so. This means simply playing this game or using the pizza screen saver uses 1000+ watts of power on my system.
In other words, it’s the worst, most inefficient screen saver ever created and you should never use it as one.
If you only have one GPU the game/pizza demo will look much emptier as it will be slower to make images. (this could be worked around by re-using images but this kind of thing isn’t really for mass consumption anyway so I didn’t worry it)
Oh, want to run my AI Tools server + app on your own computer?
Well, it’s a bit convoluted so this is only for the dedicated AI lovers who have decent graphic cards.
My app requires that you also install a special server, this allows the two pieces to be updated separately and offload the documentation on installing the server to others. (it can be tricky…)
There are instructions here, or google “automatic1111 webui setup tutorial for windows” and replace where they mention https://github.com/AUTOMATIC1111/stable-diffusion-webui with https://github.com/SethRobinson/aitools_server instead.
The setup is basically the same as my customized server *is* that one, just with a few extra features added as well as insuring that it hasn’t broken compatibility with my tools.
The dangers of letting the player choose the game subject dynamically
The greatest strength and weakness of something like this is that the player enter their own description and can shoot at anything or anyone they want.

A shirtless Mario, something I created as an, uh, example of what you shouldn’t do. Unless that’s your thing, I mean, nobody is going to know.
Unfortunately, stable diffusion weight data reflects the biases and stereotypes of the internet in general because, well, that’s what it’s trained on. Turns out the web has become quite the cesspool.
Tim Berners-Lee would be rolling in his… oh, he’s still alive actually, really underscores how quick everything has changed.
The pitfalls are many: for example, if someone chooses the opponent “terrorist”, you can guess what ethnicity the AI is going to choose.
Entering the names of well known politicians and celebrities work too – there is no end of ways to create something offensive to someone with just a few keystrokes.
Despite being a silly little tech demo nobody will see I almost changed the name to “Cupid’s Arrows” where you shoot hearts or something in an effort to side-step the ‘violence against X’ issue but that seemed a bit too… I don’t know, condescending and obvious.
So I went with a paintball theme as a compromise, at least nobody is virtually dying now.
The legality of AI and the future
Well, this is my blog so I might as well put down some random thoughts about this too.
AI image generation is currently in the hot seat for being able to mimic popular artists’ style and create copyrighted or obscene material easier than ever before. (or for a good time, try both at once)
The stable diffusion data (called the weights) is around 4 GB, or 4,294,967,296 bytes. ALL images are created using only this data. It’s reportedly trained on 2.3 billion images from just around the internet.
Assuming that’s true, 4,294,967,296 bytes divided by 2.3 billion is only two bytes per image on average. *
Two bytes is enough space to store a single number between 0 and 65535) . How can all this be possible with only one number per image?! Well, it’s simple, it’s merely computing possibilities in noise space that are tied to tokens which are tied to words and … uh.. it’s all very mathy. Fine, I don’t really get it either.
This data (and code to use it) was released to the public for free and is responsible for much of the explosion we’re seeing now.
Our copyright system has never had to deal with concepts like “AI training”. How would it ever be feasible to get permission to use 2.3 billion images, and is it really necessary if it results in only a few bytes of data per each?
I’m hoping legally we end up with an opt-out system instead of requiring permission for all training because keep this mind: If you want to remove someone from a picture or upscale it, it will do the best job if it’s been trained on similar data. Using crippled data sets will make things less useful across the board.
Copyright as it applies to AI needs to evolve as fast as the technology, but that’s unlikely to happen. We have to find the balance in protecting IP but also not at the cost of hamstringing humanity’s ability to use and create the most amazing thing since mp3s.
Image generation has gotten a lot of attention because, well, it’s visual. But the AI evolution/revolution happening is also going to make your phone understand what you’re saying better than any human and help give assistance to hurricane victims.
Any rules on what can and can’t be used for training will have implications far beyond picture tools.
* it’s a bit more complicated as some images are trained at a higher resolution, a celebrity’s face or popular artist may be in thousands of images, etc.
Uh, anyway
So that’s what I’ve been playing with the last few months. Also doing stuff with GPT-3 and text generation in general (Kobold-AI is a good place to start there).
Like any powerful tool, AI can be used for good or evil, but I think it’s amazing that an art pleb like me can now make a nice apple.
It’s still early, improvements are happening at an amazing pace and it’s going to get easier to use and install on every kind of device – but a warning:
I finally watched the video that links to this blog post. Amazing work! A colleague of mine just joined the Archimedes Institute as Creative Director due to him diving into the deep end with AI generative art. Maybe you two should meet if you haven’t already?
Thanks GB! Sure, always happy to talk AI stuff
This is awesome. Thanks for putting out dope content btw…been perusing your CODE DOJO site since your “Two guys made an MMO” post. Definitely been a motivator for me, and choosing to pursue programming as a profession :D