
So Twitter killed embedded feeds last week.
For many years I’ve had this website and others showing recent tweets as feeds because it’s easier to tweet than edit html or make blog posts and it lets people visiting my website know I’m still alive.
And now that’s impossible?!
No problem – I took a few hours to create a Mastodon account (it’s here) and fix these sites to work again. Mastodon supports rss feeds out of the box which makes embedding a feed child’s play.
This is something that neither Bluesky or Threads can currently do to my knowledge.
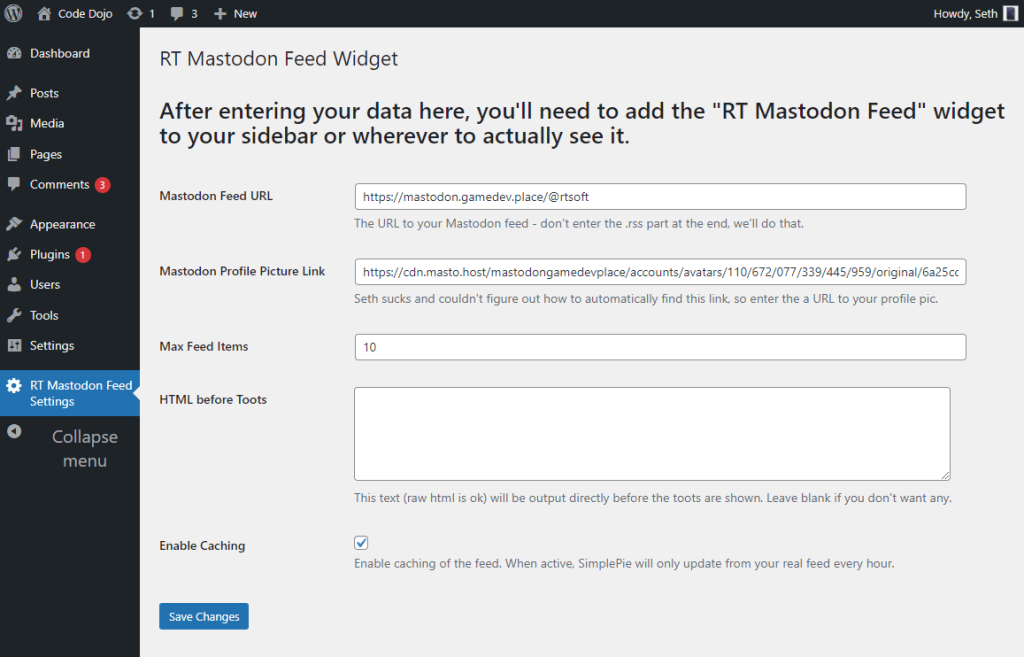
I started with this plugin and it worked, but it didn’t show movies or cache the feed so OF COURSE I had to write my own dumb widget plugin today because I’m broken like that. (Also, I knew using SimplePie would make it really easy, I use it for everything)
Anyway, if anybody wants to use my super simple WordPress plugin it’s here:
https://github.com/SethRobinson/rt-mastodon-feed
What does it look like?
look to the right of your screen and you should see it in action!
If not, it’s a piece of crap that broke already, sorry
What about embedding the feed on a site that doesn’t use WordPress?
Yeah, I’m doing that on rtsoft.com, I just ripped the guts out of my plugin and hardcoded the links and it works.
Do you still use Twitter?
Yeah, it’s how a lot of people see what I’m working on so I’ll post on both for now.
I’ve kept sane by using Control Panel For Twitter both on desktop and iPhone which removes all the crap and lets you have a friends-only feed without ads. It’s cool having retweets in a separate tab because that way I can focus on just what friends are saying first and checkout retweets only if I have the time.
Hint: It helps to have a lot of words muted, “elon” for one, uh oh, it just occurred to me, sorry if anyone thinks I’ve been ignoring them who happens to be named Elon, uh, just use email please.
Will you sign up to those other new social media sites?
Only if I have to. I put stuff off as long as possible as the last thing I need is more social media. The concept of “federated timelines” interests me though, hope we’ll be hearing more about that across the social media landscape so we can all use whatever and avoid ‘locked-in ecosystem’ hell.